

1. Importer le nécessaire
Afin de créer nos repositories, nous allons avoir besoin d’importer dans Gradle les librairies nécessaires. Donc on va dans le fichier /build.gradle. Et on ajoute « implementation 'org.springframework.boot:spring-boot-starter-data-jpa' » et « runtimeOnly 'com.h2database:h2' » à la section dependencies.

runtimeOnly, indique que l’import sera utilisé uniquement, lors de l’exécution. Nous n’avons pas besoin des imports BDD pour le développement.
Vous pouvez alors faire clic droit => Gradle => Refresh Gradle Project
2. Configurer applicaiton.properties
On ajoute les lignes suivantes dans /src/main/resources/application.properties
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=
spring.datasource.password=
spring.jpa.database-platform=org.hibernate.dialect.H2Dialectspring.datasource.url: Spécifie l’URL de connexion à la base de données.spring.datasource.driverClassName: Indique le driver JDBC à utiliser pour se connecter à la base de données.spring.datasource.username: Définis le nom d’utilisateur pour se connecter à la base de données (vide ici pour H2 en mémoire).spring.datasource.password: Définis le mot de passe pour se connecter à la base de données (vide ici pour H2 en mémoire).spring.jpa.database-platform: Spécifie le dialecte Hibernate à utiliser pour la base de données, ce qui permet à Hibernate de générer les requêtes SQL appropriées.
3. Création du top model
Pour la création de notre top model on va créer un package com.raphlys.model. Je ne ferrais pas l’affront de vous indiquer clic droit => « New » => « Package » , parce que vous vous en souvenez certainement. Dans ce package on va créer une classe TruckModel, je ne reviendrais pas non plus sur le clic droit => « New » => « Class ». Voici le corps de notre classe :
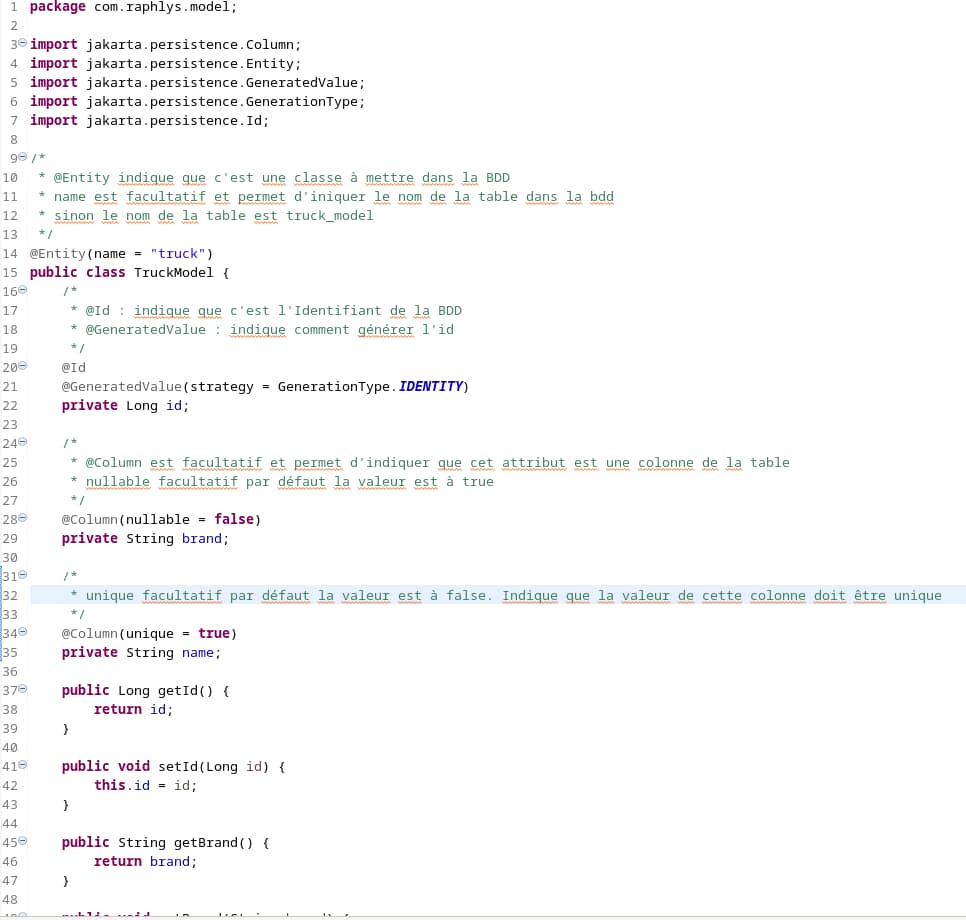
Pour les différentes options disponibles dans @Column je vous laisse vous rendre dans la javadoc => https://jakarta.ee/specifications/persistence/3.2/apidocs/jakarta.persistence/jakarta/persistence/column
Vous trouverez dans la javadoc les différentes classes et annotations utilisées et utilisables.
4. Création du Repository
On fait un nouveau package com.raphlys.repository avec la classe TruckRepository. Le contenu de la classe est le suivant :

Avec ces quelques lignes vous allez avoir accès à votre table. En étendant le linge vous permettez à vos vêtements se sécher. Mais là en étendant l’interface JpaRepository<TruckModel, Long> vous vous offrez des méthodes pour manipuler votre table. TruckModel est l’entité qui représente la table et Long le type de l’id. On pourrait avoir un id complexe, mais ce n’est pas le sujet de cet article.
Maintenant y a plus qu’à injecter notre repository dans le service et à l’utiliser.
5. Utilisation du repository
Nous allons modifier notre classe TruckService de la façon suivante :
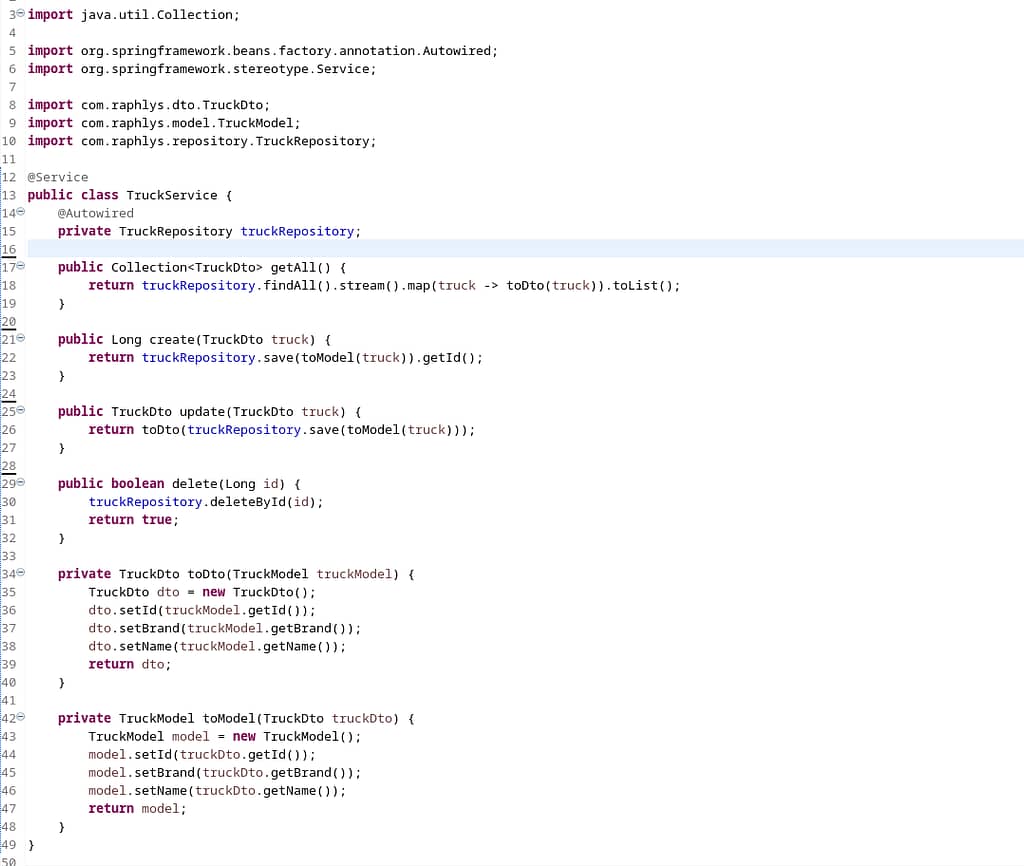
On a supprimé toute référence à notre Map et on a remplacé par TruckRepository. Attardons-nous sur les méthodes toDto et toModel. Ces deux méthodes permettent simplement de transformer un Dto en Model et inversement. On a donc comme dans le modèle MVC, la vue qui ne connaît pas le modèle et inversement, c’est le contrôleur qui fait la transformation. Cette transformation est indispensable, afin de contrôler ce que l’on envoie. Par exemple on peut filtrer de façon systématique sur un objet User le fait de ne pas envoyer le mot de passe. Mais surtout si on a une classe modèle A qui référence une classe modèle B et que la classe B référence la classe A, nous allons avoir des exceptions au moment de l’envoi au navigateur.
Les classes modèles ne sont pas des classes normales, elles peuvent utiliser des proxies pour le chargement des classes composées. Nous verrons plus tard, comment s’en servir.
truckRepository.findAll().stream().map(truck -> toDto(truck)).toList();La méthode findAll retourne les éléments de la table. Il ne faut pas l’utiliser en production, si la table fait plusieurs milliers de lignes, vous risquez d’avoir un problème. Vous trouverez la même méthode avec un paramètre Pageable.
truckRepository.save(toModel(truck)).getId();La méthode Save peut être utilisée pour un update ou un create. S’il y a la présence d’un ID la ligne de la table sera mise à jour (si elle existe sinon exception) et sinon cela créera une nouvelle ligne.
truckRepository.deleteById(id);La méthode deleteById, comme son nom l’indique permet de supprimer une ligne par rapport à son Id. Il existe d’autres méthodes de suppression. Je vous laisse regarder.
L’interface JpaRepository nous offre des méthodes prèconfigurées extrêmement pratique pour manipuler des lignes de nos tables. Je montrerais dans un prochain article comment créer sa resquête spécifique.
Et n’oubliez pas de tester!!!
Laisser un commentaire